

Este trabajo está basado en una traducción del artículo: Jiménez, R. M., Silva-López, R. B., & Olvera, F. H. (2018). The road to the library of Babel or how to manage large digital collections. In ICERI2018 Proceedings (pp. 1481-1486). IATED.
Con cambios y adaptaciones introducidos por los propios autores.
Presentamos una herramienta y un modelo para la gestión de colecciones digitales que se puede implementar en cualquier contexto relacionado con el manejo de grandes catálogos. Este enfoque puede aplicarse no solo a repositorios científicos, sino también a cualquier organización que requiera gestionar colecciones que incluyan una gran cantidad de recursos digitales. Nuestra propuesta se basa en la comunicación entre DSpace y Aleph.
DSpace es un software para repositorios documentales, de código abierto, que se utiliza comúnmente para gestionar el acceso al contenido digital publicado por las organizaciones, principalmente colecciones académicas. Aunque comparte algunas características con los sistemas de gestión de contenido y los sistemas de gestión documental, DSpace satisface una necesidad específica como sistema de archivo digital, enfocado en el soporte de catálogos y la rápida recuperación de documentos.
Por su parte, el Sistema de Almacenamiento Aleph es un sistema de almacenamiento definido por software que es confiable, escalable y flexible. Entre sus principales características destacan la disponibilidad de diferentes tipos de redundancia de datos, una separación cuidadosa entre datos y metadatos, un middleware que asegura la consistencia de los metadatos y su propio procedimiento para balance de carga y asignación, que se adapta al número y capacidades de los dispositivos de almacenamiento que lo soportan. Aleph es completamente independiente del hardware por lo tanto puede implementarse en distintas plataformas de hardware.
1. Introducción
El auge de usuarios de Internet en las últimas décadas, trajo consigo la producción de documentos digitales con tasas sin precedentes, representado grandes desafíos para mantener la buena gestión de los contenidos. Una vez que los documentos han sido organizados y catalogados, es necesario:
1. Actualizar o desarrollar mecanismos para la recuperación de contenido. Esto implica asegurar que, dada la estructura de catalogación existente, la búsqueda y acceso a la información sea eficiente.
2. Analizar la necesidad de crear mecanismos para el almacenamiento de la información. Se debe evaluar si los sistemas de almacenamiento actuales son adecuados o si se requieren nuevas soluciones para garantizar la seguridad y accesibilidad de los datos.
Es importante enfatizar la diferencia entre el contenido, que adquiere significado en un contexto cultural, y la información que lo codifica o lo transforma en bits, permitiendo construir el registro material.
La codificación de la información hace posible su almacenamiento, procesamiento e intercambio.
La información es un bien colectivo e intangible del que depende la continuidad de los procesos en las organizaciones modernas. El volumen de información que manejan estas organizaciones ha crecido y continuará haciéndolo en los próximos años. Para enfrentar esta tendencia, los directores de información (Chief Information Officers, CIO) no pueden seguir utilizando los mismos mecanismos de gestión. El almacenamiento se ha convertido en una operación estratégica que requiere una planificación cuidadosa a mediano y largo plazo. Este trabajo se centra en establecer una diferencia entre lo que entendemos por almacenamiento personal o individual y el almacenamiento de las organizaciones.
Entendemos que las personas, como legítimos propietarios, necesitan almacenar su información privada y, para ello, pueden recurrir a un dispositivo físico o virtual. En el primer caso, nos referimos a un disco permanente conectado a su computadora personal o bien, a un dispositivo portátil. En tanto que, en el segundo caso, los usuarios acceden a través de una red como la Internet, a un dispositivo que probablemente no les pertenece, donde se almacena su información. Es decir, en el primer caso, los usuarios recurren a un producto, y en el segundo, a un servicio. En cualquiera de las dos situaciones, cada usuario puede elegir de manera independiente la solución para guardar su información.
En cuanto al almacenamiento de las organizaciones, los miembros de estas se consideran usuarios que tienen atribuciones de acceso a la información que genera su organización. Sin embargo, dependiendo de las políticas de acceso pueden estar limitados en las decisiones relacionadas con el uso, almacenamiento y transporte de esa información. Existen casos en donde los usuarios no pueden llevarse copias de la información que manejan y esta solo puede almacenarse en un repositorio designado para tal propósito. También están las situaciones en las que se les exige entregar sus dispositivos de almacenamiento cuando dejan de trabajar para la organización. Los CIO tienen entre otras responsabilidades, la obligación de designar dispositivos de almacenamiento primario y secundario con el objetivo de mitigar riesgos, prever contingencias e incluso desastres. En este contexto, deben decidir si adquieren un producto o contratan un servicio para construir dichas capacidades. Sin embargo, la respuesta no es tan sencilla como en el caso del almacenamiento personal, ya que esta vez el volumen juega un papel importante [1, 2].
Podría parecer que una organización no debería ceder el control de los detalles relacionados con el almacenamiento de su información. Sin embargo, existen dos requisitos que introducen nuevos elementos en el proceso de toma de decisiones. Normalmente, el requisito de disponibilidad de la información aumenta con el tamaño de la organización. Por otro lado, la información crece incluso a tasas exponenciales, lo que significa que la gestión de dispositivos de almacenamiento puede convertirse en una tarea que demande cada vez más recursos de la propia organización. El análisis costo-beneficio debe considerar un horizonte a mediano y largo plazo, en el que la disponibilidad de la información y la escalabilidad del almacenamiento sean elementos clave a tener en cuenta [3, 4, 5].
Este trabajo presenta una herramienta que resuelve los desafíos de la gestión documental. Nuestro desarrollo se basa en una cuidadosa división de las capacidades de almacenamiento donde el argumento central es mantener este enfoque como clave para satisfacer los estrictos requisitos ya considerados. El resto del documento incluye las siguientes secciones: En la sección 2 se resumen los rasgos más destacados del Aleph, entendido como el contexto de nuestro trabajo. En la sección 3 se presenta una breve descripción de DSpace, así como la metodología que seguimos para construir la interfaz DSpace – Aleph. En la sección 4 se considera una implementación de la solución expuesta. Finalmente, en la sección 5 se discuten las conclusiones de este proyecto y sus posibilidades futuras.
2. El Aleph
El almacenamiento masivo de información representa una de las operaciones más sensibles de cualquier organización. Muchos investigadores y consultores reconocen que esta infraestructura debe basarse en un sistema distribuido y definido por software que cumpla con los requisitos de escalabilidad y disponibilidad, y que ofrezca una interfaz estándar que permita su integración con diferentes aplicaciones [6].
Un sistema de almacenamiento distribuido se implementa en un conjunto de máquinas con capacidades de almacenamiento y procesamiento, las cuales están conectadas mediante una red de alta velocidad (ver Fig. 1). La información en custodia se almacena de forma redundante en varios de estos dispositivos. El beneficio inmediato es que se logra independencia entre la información y el entorno en el que se aloja. En otras palabras, los archivos almacenados en un repositorio distribuido no dependen de un solo dispositivo para su recuperación. Si un documento se almacena en una sola máquina, el fallo de esta cancelaría su recuperación. Por otro lado, el exceso de información constituye una forma de respaldo que garantiza tolerancia a fallos y mejora la disponibilidad del sistema.
Figura 1 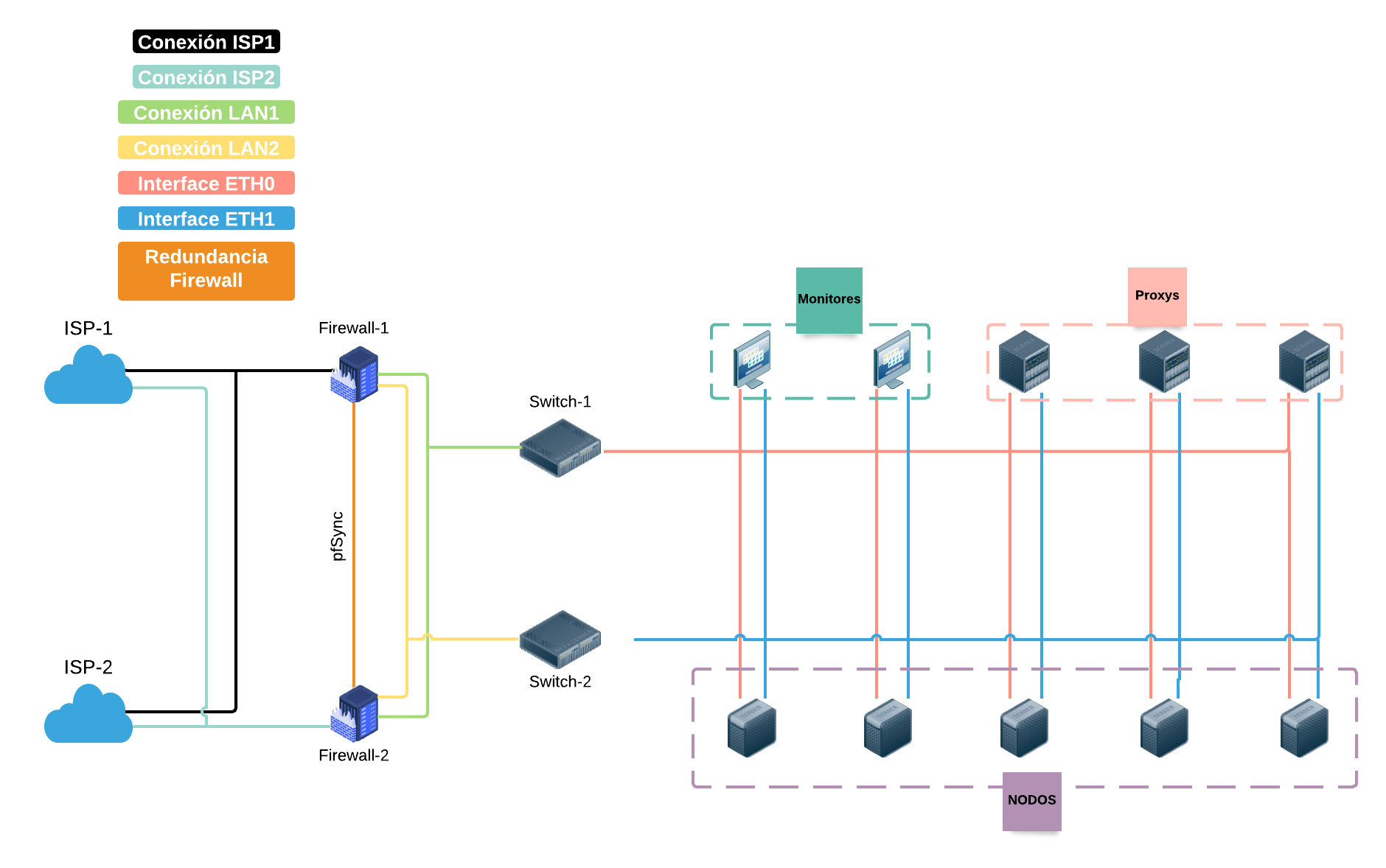
En cuanto a los sistemas de almacenamiento definidos por software; son aquellos sistemas que emplean mecanismos de software para habilitar dispositivos virtuales en los cuales se pueden realizar operaciones de almacenamiento y recuperación de información independientemente de la tecnología del dispositivo físico de soporte, su principal ventaja radica en las posibilidades que otorgan a los administradores para elegir o cambiar de proveedores o tecnología sin perder continuidad en los servicios ofrecidos.
Por otra parte las soluciones en el dominio del almacenamiento y recuperación de información deben considerar las potencialidades de la información que gestionan, con el fin de promover su uso. Es decir, se debe tener en cuenta que el almacenamiento además de ser utilizado para guardar copias de seguridad o archivos digitales, puede mejorar muchas operaciones comunes de la organización en conjunto con las aplicaciones que utilizan este servicio a través de interfaces estándar; como el trabajo colaborativo, las herramientas de apoyo a flujos de trabajo, la administración de catálogos documentales y algunas aplicaciones que requieren almacenamiento temporal. En consecuencia, se espera que dicho sistema sea compatible con protocolos estandarizados que permitan su conexión con este tipo de aplicaciones.
Los sistemas de almacenamiento pueden clasificarse en tres grandes categorías, algunas veces llamadas paradigmas: orientados a archivos, orientados a bloques y orientados a objetos.
Los archivos y los bloques organizan los datos en archivos y carpetas en una jerarquía similar a un árbol y proporcionan una ruta al archivo, además de retener una pequeña cantidad de metadatos sobre esta entidad. En el caso del almacenamiento orientado a archivos, el sistema de archivos reside en el mismo dispositivo donde se guardan los documentos que se gestionan. Mientras tanto, en el almacenamiento orientado a bloques, el sistema de archivos es externo al arreglo o conjunto de discos donde se guardan los documentos y las llamadas de entrada/salida (I/O) son gestionadas por el sistema de archivos en el servidor, requiriendo solo información a nivel de bloques para acceder a los datos en los dispositivos finales. El almacenamiento por archivos es más adecuado para la retención y acceso de archivos completos, y cuenta con sistemas de bloqueo que previenen cambios simultáneos y la corrupción de archivos. Por su parte, el almacenamiento por bloques permite cambios a los bloques dentro de documentos completos, por lo que es extremadamente adecuado para bases de datos y procesamiento transaccional.
Por otro lado, como su nombre lo sugiere, el almacenamiento basado en objetos asigna datos en contenedores aislados conocidos como objetos. Cada objeto tiene un identificador único y se almacena en un modelo de memoria plana. Esto es importante por dos razones:
i) Un objeto puede recuperarse rápidamente simplemente presentando su ID, lo que facilita mucho la búsqueda de información en un gran conjunto de datos.
ii) Los datos pueden almacenarse físicamente en un servidor local o en un servidor remoto en la nube.
El almacenamiento por objetos también proporciona mucha mayor flexibilidad para los metadatos. La escalabilidad es el punto más destacado del almacenamiento basado en objetos. Ampliar una arquitectura de objetos es tan sencillo como agregar nodos adicionales al clúster de almacenamiento.
El Sistema de Almacenamiento Aleph es un sistema de almacenamiento distribuido definido por software, que soporta el modelo de almacenamiento por objetos, y ofrece atributos de flexibilidad, confiabilidad y escalabilidad. Aleph fue desarrollado en la Universidad Autónoma Metropolitana (UAM) de la Ciudad de México, es un sistema que puede implementarse en diferentes plataformas de hardware y destaca entre sus principales características la disponibilidad de diferentes tipos de redundancia de datos, una separación cuidadosa entre datos y metadatos, un middleware que asegura la consistencia de los metadatos, y su propio procedimiento de balance de carga y asignación, que se adapta al número y capacidades de los dispositivos de almacenamiento que lo soportan.
Las organizaciones enfrentan el desafío de desplegar infraestructuras de almacenamiento escalables que soporten múltiples cargas de trabajo provenientes de diferentes aplicaciones y que proporcionen la mayor resiliencia de datos posible, considerando las limitaciones técnicas y los costos de los proveedores actuales. Aleph ofrece diferentes mecanismos para la protección de datos, incluyendo códigos para la detección y corrección de errores. Admite almacenamiento por objetos utilizando un protocolo estándar (REST), lo que facilita su integración en muchas aplicaciones comunes y personalizadas [7, 8].
3. La interfaz DSpace – Aleph
Para construir un repositorio documental es necesario contar con una plataforma de software que ofrezca un conjunto de propiedades, tales como: soporte de estándares internacionales para la descripción de recursos (Dublin Core o DICOM por ejemplo), interoperabilidad; capacidad para intercambiar información con otros repositorios, control de acceso basado en roles, definición de accesos para cada uno de los recursos catalogados (público, privado, por grupos), capacidad para escalar los recursos de almacenamiento, y garantía de disponibilidad e integridad de la información. Existe un interés global en el uso de este tipo de plataformas, lo que ha dado lugar a un amplio conjunto de soluciones, entre las cuales podemos mencionar casos como DSpace [9], OpenRepository [10], Archimed [11], Fedora [12] y Eprints [13].
Entre todos los repositorios institucionales implementados en todo el mundo, el 48% utiliza DSpace como plataforma base. DSpace es un software de código abierto que proporciona herramientas para gestionar colecciones digitales, admite una amplia variedad de documentos, incluidos libros, tesis, revistas, fotografías, películas, datos de investigación y otros tipos de contenido. Un repositorio institucional basado en DSpace se estructura en comunidades y colecciones, en el que cada comunidad contiene subcomunidades y/o colecciones, y las colecciones contienen elementos. A su vez, un elemento puede contener uno o varios archivos digitales. Los usuarios se organizan en cuentas personales y de grupo, y a cada usuario se le asignan permisos y autorizaciones que pueden variar desde acceso restringido de lectura, hasta acceso sin restricciones para escribir, leer, modificar y eliminar registros.
Entre las ventajas de DSpace destaca el hecho de que es completamente configurable y personalizable, lo que permite adaptarlo a las necesidades de las instituciones que lo adoptan. El conjunto de organizaciones que puede beneficiarse de DSpace abarca desde pequeños equipos o empresas (públicas o privadas) hasta gobiernos federales.
DSpace es una solución formada por un conjunto de APIs que ofrece una nueva forma de recopilar, organizar y preservar objetos digitales, que registran la producción documental de las organizaciones. Un repositorio institucional almacena objetos digitales que pueden ser consultados en cualquier momento. Esta condición impone un requisito de alta disponibilidad que puede verse comprometido por la capacidad y vida útil de los dispositivos de almacenamiento. Sin embargo, dado que DSpace es software de código abierto, es posible desarrollar módulos e integrarlos como nuevas APIs.
La solución que hemos desarrollado es una interfaz que conecta el servidor donde se aloja DSpace con el sistema de almacenamiento Aleph. Desde nuestra perspectiva, la cantidad de información a preservar nos llevó a pensar en una organización que divide las capacidades de almacenamiento en dos categorías principales: el primario y el secundario. El almacenamiento primario es donde inicialmente se alojan los documentos, estos dispositivos deben ofrecer una baja latencia de transferencia. Por el contrario, el almacenamiento secundario es el soporte del archivo de largo plazo y los dispositivos que lo constituyen deben ser capaces de alojar un volumen masivo de información.
La interfaz fue desarrollada siguiendo la estructura y el modelo de lógica empresarial original del proyecto DSpace e integrada en el módulo de API que implementa la funcionalidad de almacenamiento. La metodología de diseño consistió en estudiar detalladamente cada una de las APIs que originalmente forman el proyecto DSpace, así como las tecnologías, frameworks y lógica del código fuente. Una vez identificada la estructura, los módulos y las capas del software, se detectaron las entidades que gestionan el almacenamiento primario para integrar la nueva API que permite la comunicación con Aleph.
El paquete de almacenamiento de DSpace implementa un componente llamado Bitstream Manager, que se encarga de gestionar, modificar y eliminar información almacenada. Cada objeto -item- contiene bitstreams, archivos digitales entendidos como documentos en diferentes formatos y aplicaciones, tales como imágenes, videos, audio, etc. Cuando los items son catalogados y almacenados, los bitstreams asociados pasan por un proceso que les asigna un identificador y una ubicación de almacenamiento en el disco del servidor de DSpace (almacenamiento primario). Además, el Bitstream Manager asigna un nombre a cada bitstream de acuerdo con el identificador correspondiente y elimina el formato o extensión, haciendo referencia al item y los metadatos en la base de datos relacional.
Una vez almacenados los bitstreams en la ubicación definida por el algoritmo que los procesa, se notifica al usuario que el item y sus bitstreams han sido almacenados en el disco local. Cuando se completa el almacenamiento, se invoca a la API que desarrollamos para solicitar el almacenamiento de los bitstreams en Aleph (almacenamiento secundario). Esta operación se desarrolla de forma desatendida mediante la creación de un hilo independiente de DSpace. Una vez finalizada esta nueva operación, existe un servicio de depuración que permite eliminar los bitstreams del disco primario cuando no han sido consultados durante un tiempo determinado. Para invocar correctamente este servicio, el sistema debe estar basado en alguna distribución GNU/Linux.
Cuando un usuario solicita un objeto almacenado previamente, el componente Bitstream Manager realiza la búsqueda en los metadatos para determinar su ubicación en el disco primario. Si el bitstream no se encuentra en el dispositivo primario, es decir fue eliminado, el gestor envía una solicitud al Aleph para descargar el bitstream y restaurarlo en el disco local (ver Fig. 2).
Figura 2 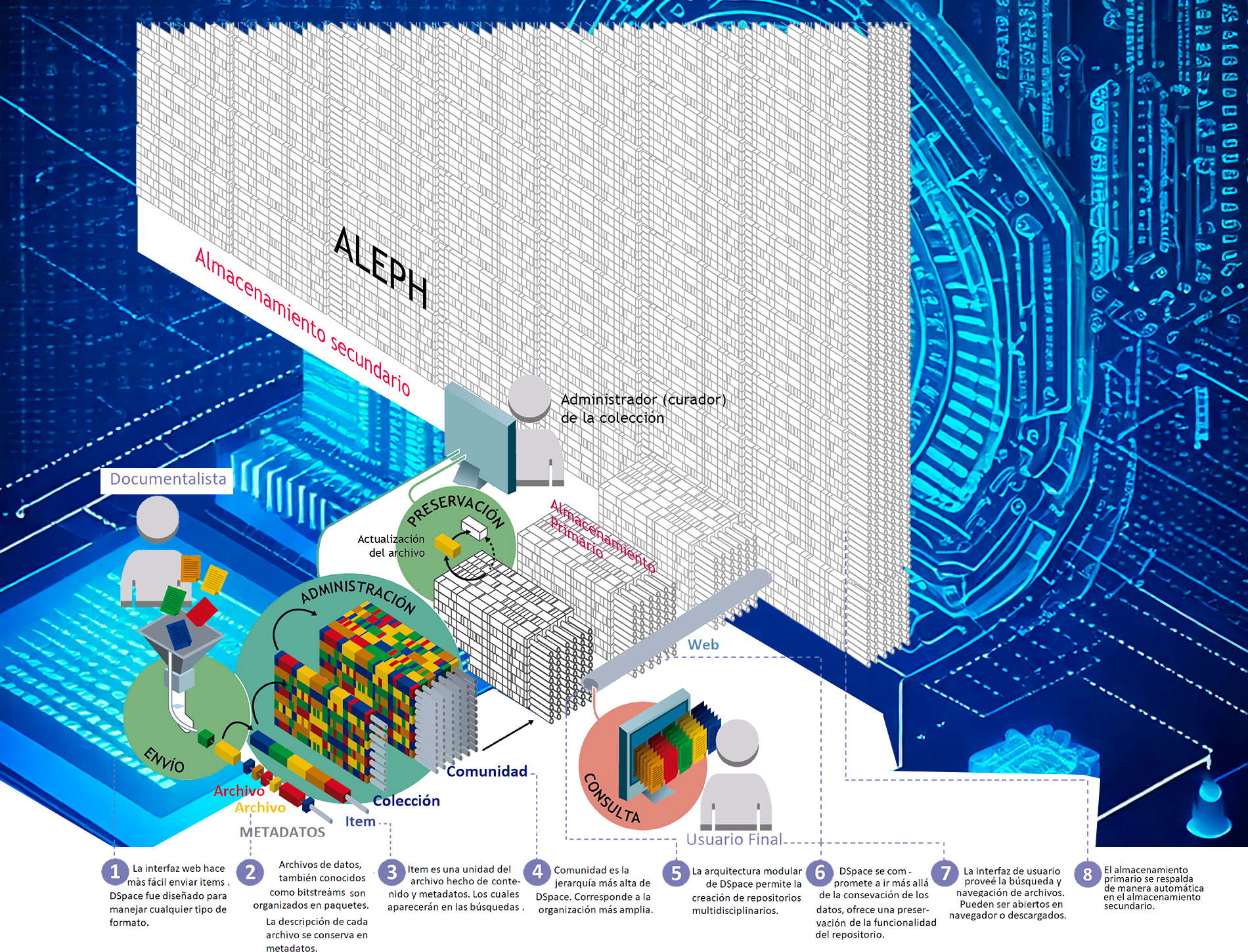
4. El Fondo Documental de la Rectoría General de la UAM
La Universidad Autónoma Metropolitana (UAM) es un organismo público descentralizado del Estado Mexicano (artículo 3 de la Ley Orgánica de la UAM), cuyas funciones sustantivas son: la docencia, la investigación y la preservación de la cultura. Derivado de las mismas y como parte de su quehacer cotidiano, la Universidad encara el reto de soportar sus procesos de manera efectiva y eficiente, lo que incluye su actualización tecnológica para la que debe considerarse un horizonte de mediano y largo plazo.
En este proyecto hemos propuesto construir un sistema de almacenamiento distribuido, definido por software, que ofrezca un espacio escalable y de alta disponibilidad, utilizando para ello la propia infraestructura de tecnologías de la información, con que cuenta la UAM. En paralelo, se ha desarrollado una solución para el manejo de catálogos documentales con el que la Universidad podría automatizar la gestión de sus documentos administrativos. Hemos presentado una propuesta basada en la solución DSpace-Aleph cuya construcción permitirá que la Universidad cumpla con los objetivos estratégicos relacionados con la gestión de su información digital, de una manera eficaz, sostenible y con visión de largo plazo. Vale la pena mencionar que muchos de estos objetivos representan también compromisos legales surgidos del gobierno federal, en materia de transparencia y preservación de documentos.
Adicionalmente, consideramos que este proyecto podría enmarcarse dentro de una iniciativa de mayor alcance, que pondría a la institución en la posibilidad de ofrecer servicios de almacenamiento bajo el modelo de nube para su propia comunidad. En el sector público existen muchas entidades que podrían beneficiarse de este modelo de gestión de la información basado en capacidades propias: las universidades y centros de investigación, las secretarías de estado, el poder judicial o el poder legislativo. Incluso, las instancias de los gobiernos estatales o municipales tendrían la posibilidad de reorganizar su capacidad instalada y aprovecharla de manera más eficiente.
5. Análisis y conclusiones
Hemos construido una interfaz que conecta un repositorio basado en DSpace, con el Sistema de Almacenamiento Aleph. La preservación de catálogos digitales es el objetivo fundamental de un repositorio. Desde nuestra perspectiva, el volumen de la información que debe ser preservada nos ha llevado a replantear la organización de las capacidades asociadas con el almacenamiento. El almacenamiento primario es donde los documentos se asignan inicialmente; se desea que estos dispositivos ofrezcan una baja latencia en la transferencia. En contraste, el almacenamiento secundario es el soporte para el archivo a largo plazo. Estos dispositivos deben ser capaces de acomodar un volumen masivo de información.
Dependiendo de las políticas de almacenamiento establecidas por la organización, los documentos migran del almacenamiento primario al secundario en algún momento de su ciclo de vida. Esta característica evita que el almacenamiento primario se sobrecargue, limita su tamaño y permite el uso de dispositivos de estado sólido, por ejemplo, como las que ofrecen latencias muy bajas, pero no grandes capacidades. Proponemos el uso de Aleph como una alternativa para el almacenamiento secundario. En nuestra solución, cada documento que se recibe en el servidor primario de DSpace se respalda automáticamente en Aleph de manera transparente. Además, los metadatos que describen la colección también se respaldan regularmente, lo que facilita los procedimientos de recuperación ante desastres. Si un documento que ha sido eliminado del servidor primario es requerido, se recuperará automáticamente desde el secundario, de manera transparente para el usuario que le solicite.
Llamamos a esta nueva organización “El modelo de biblioteca cerrada”, porque como sucede en algunas bibliotecas, no se permite a los usuarios interactuar directamente con toda la colección, la cual permanece cerrada al público (por cuestiones de seguridad). En su lugar, hay un empleado autorizado que almacena y recupera cualquier documento de las estanterías. Hemos construido un empleado automático, que es el único autorizado para interactuar con la colección completa de la biblioteca.
Consideramos que el modelo de interfaz que proponemos privilegia los aspectos de seguridad y conservación de los documentos, sin menoscabo de los tiempos de atención, ofreciendo ventajas tales como 1) el soporte ágil de varias solicitudes simultáneas, e incluso, diferentes tipos de colecciones, 2) la separación entre el espacio de consulta y el espacio de preservación, 3) la construcción del almacenamiento secundario garantiza una utilización muy eficiente y segura de la capacidad instalada.
Referencias
[1] Y. Chen and R. Sion, “To cloud or not to cloud: Musings on costs and viability,” In: Proceedings of the Second ACM Symposium on Cloud Computing, SOCC ’11, New York, NY, USA, pp. 1–29, 2011.
[2] R. Chow, P. Golle, M. Jakobsson, E. Shi, J. Staddon, R. Masuoka and J. Molina, “Controlling data in the cloud: outsourcing computation without outsourcing control,” In: Proceedings of the 2009 ACM Workshop on Cloud Computing Security, CCSW ’09, pp. 85–90, 2009.
[3] I. Ion, N. Sachdeva, P. Kumaraguru and S. Capkun, “Home is safer than the cloud! Privacy concerns for consumer cloud storage,” In: Proceedings of the Symposium on Usable Privacy and Security (SOUPS 2011), Pittsburgh, PA, USA, July 2011.
[4] S. Singh and T. Jangwal, “Cost breakdown of public cloud computing and private cloud computing and security issues,” International Journal of Computer Science and Information Technology (IJCSIT) vol. 4, pp. 17–31, April 2012.
[5] E. Walker, W. Brisken and J. Romney, “To lease or not to lease from storage clouds,” Computer vol. 43, no. 4, pp. 44–50, 2010.
[6] P. Yianilos and S. Sobti, “The Evolving Field of Distributed Storage,” IEEE Internet Computing, vol. 5, no. 5, pp. 35-39, September 2001.
[7] M. O. Rabin, “Efficient dispersal of information for security, load balancing, and fault tolerance”, Journal of the ACM (JACM), vol. 36, no. 2, pp. 335-348, 1989.
[8] M. Quezada-Naquid R. Marcelín-Jiménez and J.L. González-Compeán, “Babel: The Construction of a Massive Storage System,” International Journal of Web Services Research IJWSR, vol. 13, no. 4, October-December 2016.
[9] C. Wilper et al. DSpace 4.x Documentation. 2016. duraspace.org. Sitio web: https://wiki.duraspace.org/display/DSDOC4x
[10] http://www.openrepository.com/
[11] http://www.archimed.fr/
[12] https://duraspace.org/fedora/
[13] http://www.eprints.org/uk/
Visitas: 1525
